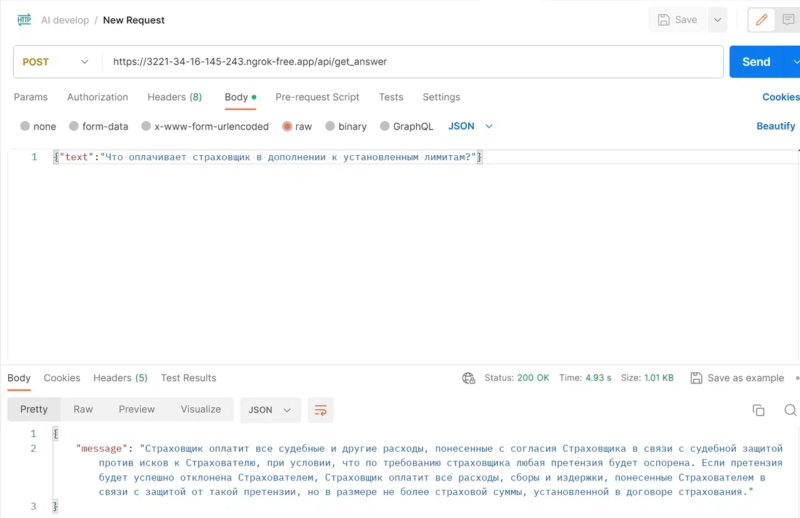
В продолжение другой статьи по теме интеграции Aimylogic c Битрикс рассмотрим как реализовать следующий алгоритм:
- Клиент звонит и попадает на голосовой бот. Оставляет заявку в ServiceDesk (например, Битрикс).
- Время обработки сервисным инженером заявки, созданной голосовым ботом, например, 2 дня.
- Нетерпеливый пользователь, не дождавшись звонка от инженера, повторно звонит и попадает на голосового бота Aimylogic.
- Голосовой бот должен посмотреть, за последнее время были ли созданы заявки от пользователя с того-же номера.
- Если такие заявки есть, то голосовой бот должен успокоить клиента, сообщив, что в системе уже есть заявка. Звонок связан с новой проблемой или с ранее зарегистрированной.
- Если клиент озвучит, что проблема другая, то должна создастся новая заявка.
Получение контакта клиента в Bitrix через REST API
Итак, Aimylogic определил с какого номера пришел звонок и ему нужно по этому номеру определить сервисные заявки для которых указан контакт с этим номером. Для определения есть ли клиент с указанным номером $client_phone в базе контактов Битриска используется следующий запрос:
https://xxxxxxxx.ru/rest/177/xxxxxxxxxxxx/crm.duplicate.findbycomm.json
{
"entity_type": "CONTACT",
"type": "PHONE",
"values": [ "$client_phone" ]
}
В ответе берем переменную $httpResponse.result в которой передается ID контакта.
Напомню, что добавляли смарт-процесс используя следующий POST запрос:
https://xxxxxxxxxxx.ru/rest/177/xxxxxxxxxxxxxxx/crm.item.add.json
{
"entityTypeId": "158",
"fields": {
"SOURCE_ID": "14",
"contactId": "$contact_id",
"ufCrm3_1680255422": "$equipment",
"ufCrm3_1680254883": "$client_city",
"ufCrm3_1680261235": "$question",
"ufCrm3_1687168305": "$mobilePhone",
"ufCrm3_1680261458": "$productiondate",
"ufCrm3_1697115862": "$equipment_state"
}
}
Соответственно, нам надо получить список смарт-процессов «сервисная заявка» у которых в поле «contactId» прописан полученный ранее ID контакта. Протестируем запрос в Postman на примере контакта с известным номером мобильного телефона. Получим несколько ID по номеру:
{
"result": {
"CONTACT": [
14116,
14118
]
},
"time": {
"start": 1699808317.849979,
"finish": 1699808317.890918,
"duration": 0.0409390926361084,
"processing": 0.004055976867675781,
"date_start": "2023-11-12T19:58:37+03:00",
"date_finish": "2023-11-12T19:58:37+03:00"
}
}
Видим, что с указанным номером в Битриксе есть два контакта. Контакты были созданы через разные источники. Например, через форму обратной связи и обращение через голосового бота. Считаем, что это аномалия, которую надо устранить дополнительной проверкой, чтобы исключить дублирование при создании контактов с одним номером телефона.
Посмотрим как выглядит ответ для номера у которого точно один контакт в Битриксе:
{
"result": {
"CONTACT": [
14111
]
},
"time": {
"start": 1699809721.426188,
"finish": 1699809721.46897,
"duration": 0.04278206825256348,
"processing": 0.005627155303955078,
"date_start": "2023-11-12T20:22:01+03:00",
"date_finish": "2023-11-12T20:22:01+03:00"
}
}
Тот-же массив «CONTACT», т.е. нам достаточно в Aimylogic взять первый элемент в этом массиве.
function getContact(contacts) {
try {
$obj = JSON.parse(contacts);
if ("CONTACT" in $obj) {
if ($obj.CONTACT.length > 0)
{
$contact = $obj.CONTACT[0];
}
}
} catch (e) {
return -1
}
return $contact
}
$contact = getContact($contacts)
Получение сервисной заявки (смарт-процесс) клиента в Bitrix через REST API
Чтобы получить сервисную заявку к которой привязан найденный контакт воспользуемся методом crm.item.list:
https://xxxxxxxxx.ru/rest/177/xxxxxxxxxxxxx/crm.item.list.json
{
"entityTypeId": 158,
"filter": {
"=contactId": "14111"
}
}
После выполнения запроса к Битриксу получаем JSON в котором возвращается найденная сервисная заявка со всеми нужными нам полями. Полей много, поэтому заменил на …….
{
"result": {
"items": [
{
"id": 2214,
"title": "Сервисная заявка #2214",
"contactId": 14111,
........
"entityTypeId": 158
}
]
},
"total": 1,
"time": {
"start": 1699811918.669397,
"finish": 1699811918.71892,
"duration": 0.04952287673950195,
"processing": 0.021754980087280273,
"date_start": "2023-11-12T20:58:38+03:00",
"date_finish": "2023-11-12T20:58:38+03:00"
}
}
Чтобы сократить нагрузку на сервер и сократить трафик, можно выбирать в запросе только нужные поля:
{
"entityTypeId": 158,
"select": ["contactId", "stageId", "id", "createdTime"],
"filter": {
"=contactId": "14111"
}
}
Соответственно, создаем в AimyLogic HTTP запрос POST к методу crm.item.list.json и в body прописываем:
{
"entityTypeId": 158,
"filter": {
"=contactId": "$contact"
}
}
Результат $httpResponse.result помещаем в переменную $items. И далее обрабатываем полученный JSON следующим образом:
function getItem(items) {
try {
$obj = JSON.parse(items);
if ($obj.items) {
if ($obj.items.length > 0)
{
$item = $obj.items[0];
}
}
} catch (e) {
return -1
}
return $item
}
$item = getItem($items);
$item_created = -1;
if ($item != -1) {
$item_id = $item.id;
$item_created = $item.createdTime;
}
Все отрабатывает нормально. Получаем сервисную заявку и берем дату создания.
Определение срока давности сервисной заявки
Осталось найти разность между моментом, когда клиент позвонил повторно и датой ранее созданной сервисной заявки:
function getDateDifference(isoDateStr)
{
try {
$date1 = new Date(isoDateStr);
$date2 = new Date();
return ($date2.getTime() - $date1.getTime()) / (1000 * 3600 * 24);
} catch (e) {
return Number.MAX_VALUE;
}
}
if ($item_created != -1) {
$daysdiff = getDateDifference($item_created);
}
Блоки кода целесообразно вставлять в блоки условий перед проверкой условия. Т.е. проверяем, что результат на выходе функции равен -1 и тогда отправляем на сообщение об ошибке, точнее отправляем клиента по стандартному маршруту, когда бот будет задавать ему перечень стандартных вопросов. По ветке else отправляем на следующий этап обработки.
Можно реализовать проверку на дату непосредственно в запросе на поиск нужных сервисных заявок (смарт-процессов). Для этого нам надо отфильтровать заявки у которых поле createdTime старше текущей даты не более, чем на n дней. Т.е. берем текущую дату, вычитаем n дней и смотрим все записи у которых createdTime больше полученной даты.
{
"filter": {
">createdTime":"2020-03-19T02:00:00+02:00"
}
}
Пример финального запроса будет выглядеть следующим образом:
https://xxxxxxxxx.ru/rest/177/xxxxxxxxxxxxx/crm.item.list.json
{
"entityTypeId": 158,
"select": ["contactId", "stageId", "id", "createdTime"],
"filter": {
"=contactId": "14111",
">createdTime": "2023-11-11T15:08:13+03:00"
}
}
Итак, после обработки полученной даты создания сервисной заявки получили разность дат в днях и можно принимать решения, озвучить клиенту, что он недавно создал заявку и она в обработке или позволить создать новую заявку. Можно дополнительно уточнить у клиента, обращение по старой заявке или какая-то новая проблема.
В этот запрос надо ещё добавить поиск только тех заявок у которых статус stageId удовлетворяет необходимым. Например, если stageId — SUCCESS, при этом дата создания заявки менее n дней назад, то:
- Либо что-то пошло не так и у клиента возникли проблемы с этой заявкой. Тогда нужно спросить его об этом и сменить статус (переоткрыть), чтобы доделать.
- Либо у клиента действительно все решено, но возник новый вопрос и надо создать новую заявку.
Поскольку здесь действия вариативные, нельзя включать в предфильтрацию stageId и фильтровать, например, только заявки у которых состояние SUCCESS.
Определение даты создания самой свежей сервисной заявки
Теперь нужно учесть момент, что у клиента с одним и тем-же номером телефона, но, например, несколькими контактами в Битриксе, может быть несколько сервисных заявок созданных в разное время. Соответственно, нужно пройтись по всем его заявкам и найти самую свежую. Гипотетически, если заявка была создана относительно недавно (в пределах 2-3 дней), то пользователь перезванивает по ней, поскольку сервиcные инженеры ещё не дошли.
После выполнения HTTP запроса на получение списка контактов, конвертируем в массив $contacts.
function getContact(contacts) {
try {
$obj = JSON.parse(contacts);
if ("CONTACT" in $obj) {
if ($obj.CONTACT.length > 0)
{
return $obj.CONTACT;
}
}
} catch (e) {
return -1
}
}
$contacts = getContact($contacts);
Склеиваем элементы массива в строку для передачи в HTTP POST запрос. Из id контактов должно получится что-то вроде: [«14116», «14118», «14142»]
//Функция склеивает массив в строку для POST запроса. Например, ["14116", "14118", "14142"]
function getContactsList(contacts)
{
try {
return "[\"" + contacts.join("\", \"") + "\"]";
} catch (e)
{
return "[]";
}
}
$contacts_str = getContactsList($contacts)
Теперь подаем результат в HTTP POST запрос Aimylogic.
{
"entityTypeId": 158,
"select": ["contactId", "stageId", "id", "createdTime"],
"filter": {
"=contactId": "$contacts_str",
">createdTime": "$minStartDate"
}
}
После выполнения запроса в переменной $items = $httpResponse.result будет JSON с массивом ВСЕХ сервисных заявок, которые привязаны к ВСЕМ номеру телефона клиента.
Ну и далее перебираем все даты создания сервисных заявок и находим сервисную заявку с наиболее близкой датой.
function getNewestItem(items) {
try {
$obj = JSON.parse(items);
$lastDate = new Date(1975, 10, 16); //Инициализируем произвольной датой в прошлом.
$newest_item = -1;
if ($obj.items) {
if ($obj.items.length > 0)
{
for ($i = 0; $i < $obj.items.length; $i++) {
try
{
$item = $obj.items[$i];
$item_currentDate = new Date($item.createdTime);
if ($item_currentDate > $lastDate)
{
$lastDate = $item_currentDate;
$newest_item = $item;
}
} catch (e) {
}
}
return $newest_item;
}
}
return -1;
} catch (e) {
return -1;
}
}
$item = getNewestItem($items)
Высчитываем разность между датами, как делали это раньше. Для диагностики при отладке можно вывести информацию в блоке «Синтез речи»:
if ($item != -1) {
$item_created = $item.createdTime;
$date1 = new Date($item_created);
$date2 = new Date();
$daysdiff = getDateDifference($item_created);
}
Далее алгоритм Aimylogic затачиваем под проверку разницы дат и дополнительным вопросам, а уверен ли пользователь, что это не повторная заявка.